

Tags
Share
In our last article, we scrutinized the impact of GenAI on software development. The result was an experiment that gathered empirical data on the impact of market-leading Generative AI software development tools. That experiment is ongoing, and we have already uncovered several limitations.
GenAI technology has proven adept at digesting large volumes of structured and unstructured data to generate content. It’s hardly surprising then that this tech is expected to substantially improve SDLC productivity. The hype surrounding GenAI has even fueled expectations that it will soon replace engineers—but as far as we can tell, this is simply not true.
The Science Is Only as Good as Your Lab Tools
There isn’t a single tool on the market capable of digesting all available product-related knowledge (apart from code) to assist teams with software delivery. So, how do the leading products on the market compare?
- GitHub Co-Pilot is second to none for coding, refactoring, debugging, and analyzing code. However, it’s a tool for engineering roles, not for Product Owners (POs), Designers, and Managers. It has a limited capacity for ingesting information and cannot yet use requirements, architecture documents, wireframes, and other non-code product knowledge.
- ChatGPT is a wonderful generalist, but it knows nothing about your specific product straight out of the box. When you try to fill in these gaps, you immediately run into issues. Case in point: the vanilla version has a context limitation of 128k tokens which means you can only feed it one 300-page book. That’s simply not enough for many of our projects, where requirements alone span many volumes.
- Enterprise search tools like Glean feature hundreds of integrations and can beautifully synthesize information. However, they don’t yet curate information for specific software development roles, such as POs, Developers, Designers, Support Engineers, QAs, etc.
Currently, no tool addresses all the gaps highlighted above. We project that it will take 6-18 months for the market to release a robust tool that covers everything—if it ever does.
Faced with such a long wait and the looming uncertainty, we decided to build our own accelerator.
How Do You Build the Ideal SDLC Lab Tool?
We started with the data.
All knowledge about a software product is spread across different data sources such as code, databases, requirements, plans, roadmaps, estimations, logs, UI/UX designs, and architecture diagrams.
To implement a new feature without GenAI tools, a developer has to go through all that data personally. For example, they’ll analyze requirements in Jira, understand the codebase in GitHub, and assess the impact of the data schema in a database like Postgres.
The ideal tool should speed up the process of learning from that data. Even better, it should be able to aggregate more data than a person could and explain it to them in a way that makes sense no matter their job, product type, or project stage.
Below is a screenshot of Exadel Lumea, version 1 of our AI-powered SDLC accelerator. True to its name, it sheds light on software development, helping teams navigate complexity with clarity.
We’re already deep into experimenting with it, and so far, so good.
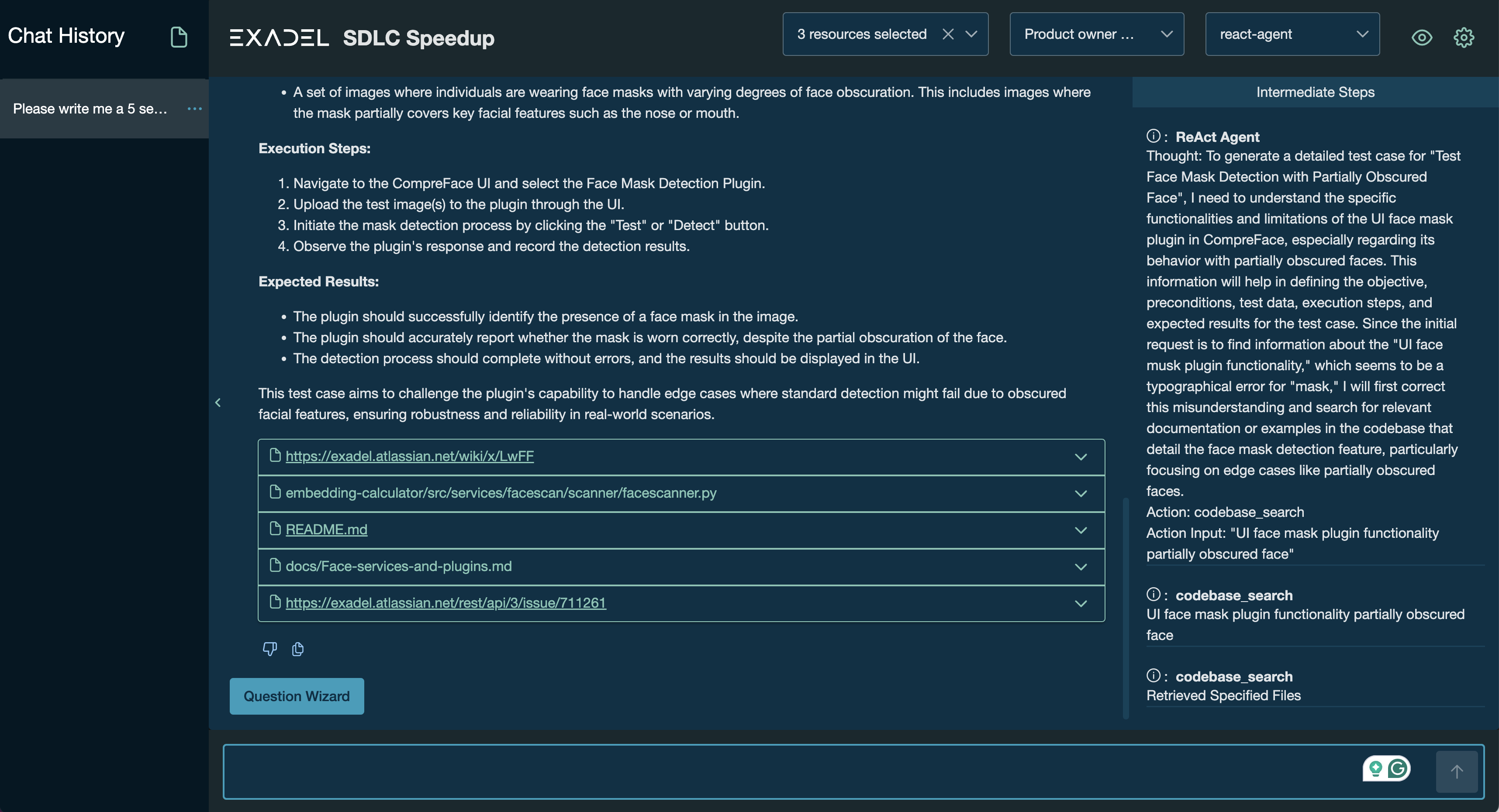
Exadel Lumea v1—Aspirations
An expert on any software product.
Exadel Lumea can handle all manner of structured and unstructured data and can be integrated with any custom or proprietary knowledge sources. We purposefully built it this way to give it the level of versatility and customizability to enable all roles participating in the SDLC—not just engineering roles. We have support for a large number of standard integrations like Jira, Github, Azure, DevOps, etc., but for non-standard products, we also included a custom integration protocol, which enables us to get insights from any data type imaginable.
It curates knowledge for any role.
As you can see in the screenshot, there is a familiar chat interface where any team member can ask questions. The tool aggregates the knowledge from all integrated data sources and can do analysis/search (in the form of Q&A) on top of all that data. This is extremely useful for all roles participating in every stage of the SDLC.
For example, the tool provides an interface for non-technical POs to ‘talk’ with the product code in PO language. For developers, it helps them navigate lesser-known functionality and logic during legacy modernization projects and less familiar (or even unfamiliar) technologies.
It’s pretty darn accurate.
We’ve all heard horror stories about LLMs quoting Shakespeare plays that were never written, but there is a way around this. By employing Retrieval Augmented Generation Patterns (RAG), the tool shows the original source of all information it generates. Like any AI, Lumea will not be 100% accurate, but at least it has to tattle on its sources.
The Experimentation Begins
To put Lumea’s promises to the test, the team has already started experimenting with various roles and use cases. Below, you can find a mix of experiments in progress and some ideas to try next.
We’ll definitely be releasing hard data in a follow-up article.
Onboarding and Team Management (All Roles)
Depending on the project’s complexity and the availability of other team members, it can often take up to nine months for people to reach optimal productivity after onboarding. To speed this up, we’ve been piloting Exadel Lumea as a personal guide for new team members, answering their questions throughout the onboarding process. We also used the tool to create and maintain traditional onboarding materials for different roles, even creating quizzes so newcomers can learn faster and we can track their progress.
The same ideas can be applied to restructuring teams or replacing third-party vendors—typically a complicated endeavor. The tool can be used to rapidly replace teams, scale them up or down, and conduct any amount of knowledge transfer imaginable.
Creating User Stories and Backlog Reviews (PO, Project Manager, BA)
While most savvy POs already use ChatGPT to create their user stories, it currently comes with the context size limitations mentioned above.
Using Lumea, our POs can access a host of knowledge to create new user stories without restrictions. Rumor has it that ChatGPT is working on plugins to increase its data sources, but Lumea is already helping our POs write user stories. It does this by accessing existing code, user stories, the product roadmap, the UI/UX, architecture, data schema, and project-specific standards such as the definition of ready.
When conducting backlog refinement activities to spot inconsistencies, duplicates, etc., POs can automatically connect to Jira and/or Azure DevOps and review the proposed scope versus defined criteria.
Analyzing, Converting, and Testing Code (Software Engineer)
Written in antiquated languages such as Visual Basic and Java Server Faces, legacy code reads like an ancient Sumerian tablet—but without the enthusiastic scholars lined up to decipher it. Instead, you have retirees and people who have long since forgotten how they built it, what it does, and how it works.
We’ve been actively using Exadel Lumea to understand code dependencies for executing major refactoring without missing or breaking the essential elements. Our researchers are using the tool to talk with the legacy code and can create architecture diagrams, facilitating improved analysis to identify more efficient ways to modernize it automatically.
It’s also impacting the quality of our software.
Our developers have been using Lumea to create different types of automated tests. We’ve found that it has already drastically reduced the amount of time it takes to create unit tests and their accompanying documentation. The quality is much better because the tests are created with a much broader contextual understanding of the product. The system analyzes not only the code but also requirements such as data schema, existing tests, etc.
IT Support
The process of handing over software to support is the most knowledge-heavy stage of development. This process typically involves creating and updating volumes of handover documentation for support teams, an acceptance process where the materials are received and validated, onboarding, handing over the operation, and support, followed by a phase of continuous enrichment.
All of that information is held in documentation, user guides, configuration, and installation guides. It needs to be continuously updated to ensure that resolved issues inform or even prevent future issues. The support team also needs to be in regular communication with product users—another area where the team could use Lumea to gain more in-depth knowledge of the product to address a unique concern.
Where Lumea truly makes a difference is in improving the performance of support teams.
With the tool, teams can use semantic search to learn from extensive documentation and other product knowledge sources like roadmaps, code logs, ticket trackers, etc. In turn, this helps to facilitate faster responses, quicker resolutions, and fewer re-opens or new issues created by fixing the existing issues.
Ultimately, this improves product quality and supports better customer experiences.
If We Build It, Will They Use It?
We’re excited about the future of Exadel Lumea and its application in our organization as well as for our clients. We are currently piloting the solution across internal and client projects.
The next big hurdle is adoption.
Our delivery leadership may think Lumea is brilliant, but if a real-life team doesn’t see the value, this productivity tool will be destined to crash and burn.
Exadel Lumea is anything but a plug-and-play solution. It’s more like an emerging mindset about what comes next for our industry and an exploration of how we might get there.
If that sounds flaky, don’t worry. We’re also going to measure the hell out of this solution and see if we can beat the current market tools, though that might just be a bit of hubris on our part!
In our next article, we’ll discuss the human aspect of these new AI tools and why people embrace or avoid AI-powered software development.
Sure, AI can help write code — but what about the rest?
Speak with the creators of Exadel Lumea about accelerating your entire SDLC.
Geeks Only
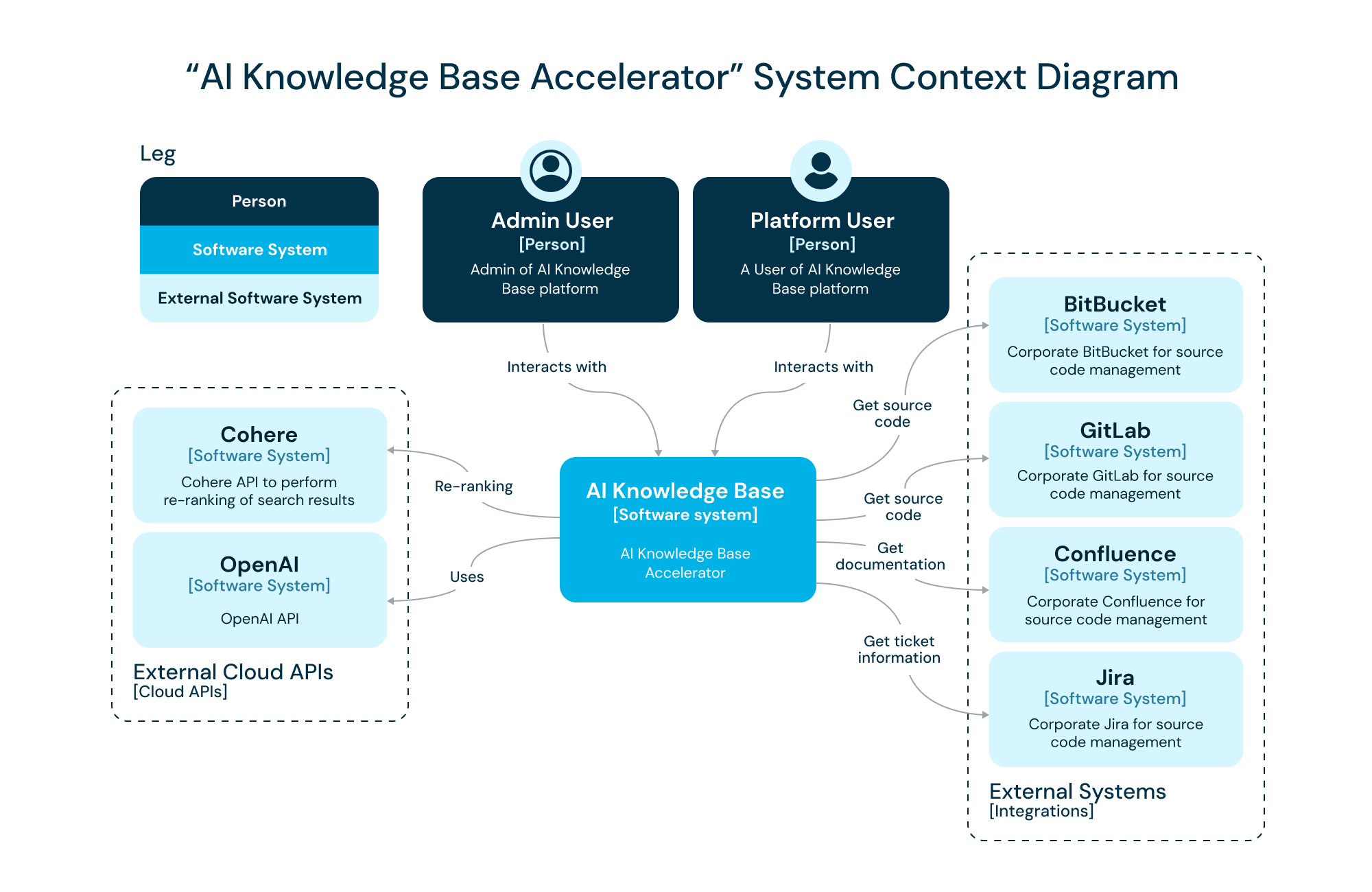
1. System Overview and External Dependencies
Exadel Lumea is a robust system designed to integrate and process volumes of data from various sources.
Its architecture is built around several key external dependencies:
- Cohere API: Used to re-rank search results to enhance relevance and user experience.
- OpenAI API: Powers the natural language processing capabilities, enabling the chat-like interface that users interact with.
- Code Repositories: Source code repositories from which the system pulls code data.
- Corporate Wikis (Confluence, Sharepoint): Documentation management system from which the system retrieves technical documentation.
- Ticket Trackers (Jira, Azure DevOps): Issue tracking system that provides the system with ticket information.
- Custom knowledge sources: we can add information from any knowledge source by importing a file
These integrations ensure that the AI Knowledge Base Accelerator is continuously fed with up-to-date information, making it a highly dynamic and reliable knowledge management tool. Additional integrations are added regularly to ensure efficient integration with all existing product knowledge sources.
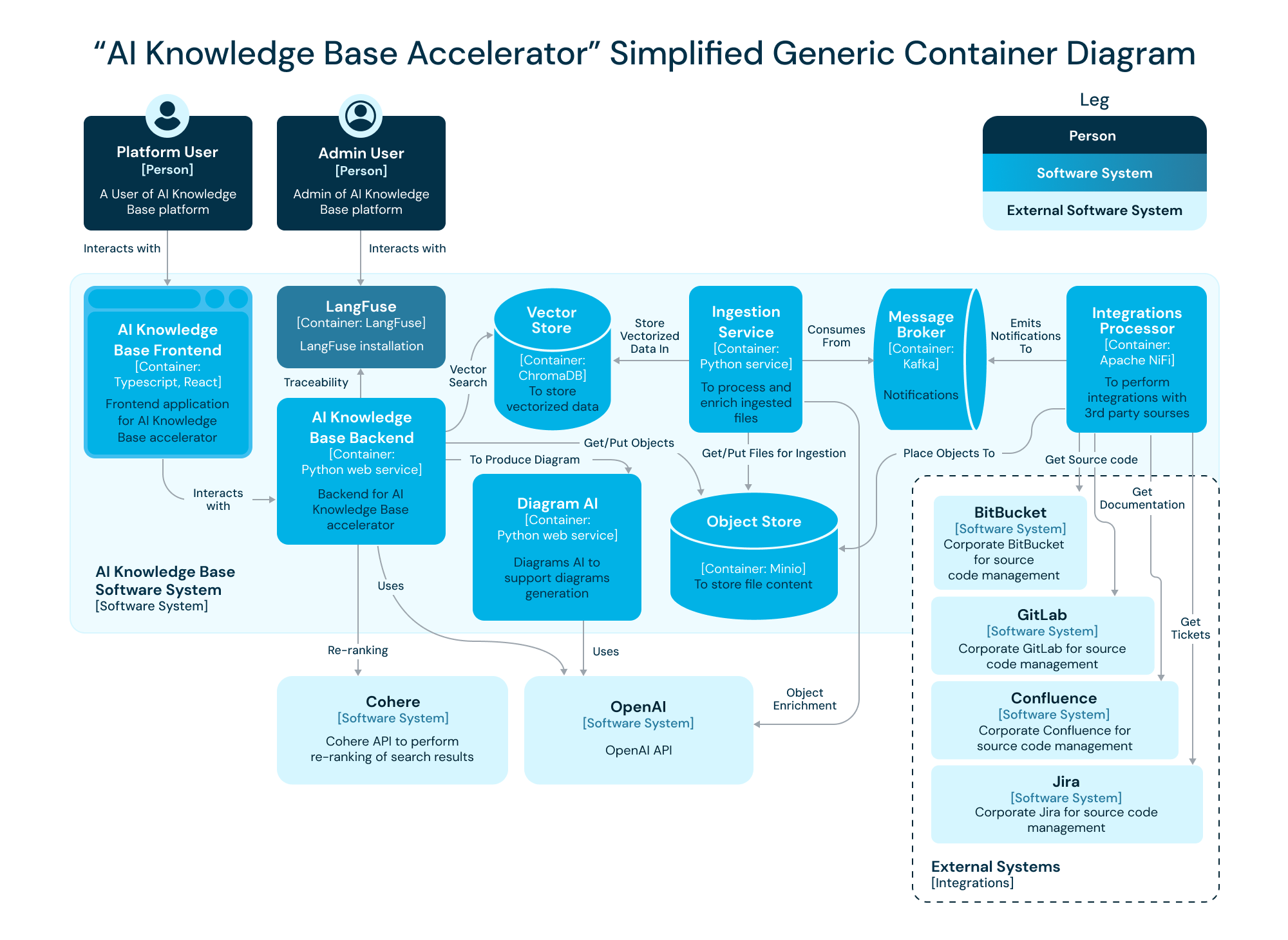
2. Distributed System Architecture
The AI Knowledge Base Accelerator is a distributed system that leverages a containerized architecture. Each component within the system runs independently in its container, allowing for scalability, flexibility, and fault tolerance.
The main containers include:
- AI Knowledge Base Frontend: A React-based interface that users interact with.
- AI Knowledge Base Backend: A Python web service that processes user requests and manages interactions with other system components.
- Vector Store: Stores vectorized data, enabling efficient retrieval based on vector searches.
- Ingestion Service: Handles data ingestion and processing, enriching raw data before it’s stored.
- Object Store: Temporary storage for raw data files prior to processing.
- Message Broker: Manages communication between components, particularly for event-driven data updates.
- Integrations Processor: Manages the data flow from external systems like BitBucket, GitLab, Confluence, and Jira into the AI Knowledge Base.
This distributed setup ensures that the system can handle large-scale data ingestion and retrieval tasks across various environments, providing a scalable solution that can evolve with the needs of the organization.
3. General Overview of Data Flows
The system operates with two primary data flows: Write Flow and Read Flow.
- Write Flow: This is the process by which data is ingested from external systems, processed, and stored in a format that allows for efficient querying and retrieval.
- Read Flow: This is the process by which data is retrieved from the storage, processed, and presented to the user based on their queries.
Each flow is crucial to the system’s overall functioning, ensuring that data is current and easily accessible.
4. Detailed Description of Write Data Flow
The Write Data Flow is designed to ensure that data from external sources is continuously ingested, processed, and stored in a manner that allows for rapid retrieval and analysis.
- Data Ingestion: The Integrations Processor continuously pulls data from external sources like BitBucket, GitLab, Confluence, and Jira.
- Temporary Storage: Raw data is initially stored in the Object Store as files or objects, providing a staging area before processing.
- Data Processing and Enrichment: The Ingestion Service consumes these files from the Object Store, processes them (including vectorization for text data), and enriches the data.
- Data Storage: Processed data is then stored in the Vector Store, where it’s converted into vectorized formats that facilitate efficient search operations.
- Notification: The Message Broker emits notifications to other components that new data is available, ensuring the system is updated in real-time.
5. Detailed Description of Read Data Flow
The Read Data Flow is centered around efficiently retrieving and presenting data to the user.
- User Query: A user interacts with the AI Knowledge Base Frontend, entering a query through the chat-like interface.
- Request Handling: The query is sent to the AI Knowledge Base Backend, where it’s processed. The backend uses the OpenAI API for natural language processing and the Cohere API for re-ranking search results as necessary.
- Data Retrieval: The backend queries the Vector Store to retrieve relevant vectorized data based on user input.
- User Presentation: The processed and relevant data is then returned to the AI Knowledge Base Frontend and presented to the user in an easily digestible format.
.png)





